Let $\left(\mathbf{u}{t}\right){0 \leq t \leq T}$ be an $m$-dimensional process and $$ \begin{aligned} &\mathbf{a}:[0, T] \times \Omega \rightarrow \mathbb{R}^{m}, \mathbf{a} \in \mathcal{C}{1 \mathbf{w}}([0, T]) \ &b:[0, T] \times \Omega \rightarrow \mathbb{R}^{m n}, b \in \mathcal{C}{1 \mathbf{w}}([0, T]) \end{aligned} $$ The stochastic differential $d \mathbf{u}(t)$ of $\mathbf{u}(t)$ is given by $$ d \mathbf{u}(t)=\mathbf{a}(t) d t+b(t) d \mathbf{W}(t) $$ if, for all $0 \leq t_{1}<t_{2} \leq T$ $$ \mathbf{u}\left(t_{2}\right)-\mathbf{u}\left(t_{1}\right)=\int_{t_{1}}^{t_{2}} \mathbf{a}(t) d t+\int_{t_{1}}^{t_{2}} b(t) d \mathbf{W}(t) $$
Let $A$ be a nonempty subset of a metric space $(X, d)$. Define $$ d_{A}(x):=\inf {d(x, a): a \in A}, \quad x \in X . $$ Then $d_{A}$ is continuous. (Geometrically, we think of $d_{A}(x)$ as the distance of $x$ to $A$.)
We give a proof even though it is easy, because of the importance of this result. Let $x, y \in X$ and $a \in A$ be arbitrary. We have, from the triangle inequality $d(a, x) \leq d(a, y)+d(y, x)$, $$ \begin{aligned} &d(a, y) \geq d(a, x)-d(y, x) \ &d(a, y) \geq d_{A}(x)-d(y, x) \end{aligned} $$ The inequality says that $d_{A}(x)-d(y, x)$ is a lower bound for the set ${d(a, y): a \in A}$. Hence the greatest lower bound of this set, namely, $\inf {d(a, y)=a \in \backslash A} n d$ is greater than or equal to this lower bound, that is, $$ d_{A}(y) \geq d_{A}(x)-d(y, x) $$
with measurement equation $$ z(k)=\left[\begin{array}{ll} 1 & 0 \end{array}\right] x^{i}(k)+w(k) $$ The models differ in the control gain parameter $b^{i}$. The process and measurement noises are mutually uncorrelated with zero mean and variances given by $$ E[v(k) v(j)]=0.16 \delta_{k j} $$ and $$ E[w(k) w(j)]=\delta_{k j} $$
证明 .
The control gain parameters were chosen to be $b^{1}=2$ and $b^{2}=0.5$. The Markov transition matrix was selected to be $$ \left[\begin{array}{ll} 0.8 & 0.2 \ 0.1 & 0.9 \end{array}\right] $$ For this example $N=7$, and the cost parameters $R(k)$ and $Q(k)$, were selected as $$ R(k)=5.0 \quad k=1,2, \ldots, N-1 $$
Proof: Since $f(d)$ is the minimal polynomial of $\boldsymbol{F}, p(d)$ can be factored as $$ p(d)=g(d) . f(d) $$ for some polynomial $g(d)=\sum_{i=0}^{s} b_{i} d^{s-i}$ Let $z_{k}$ and $\bar{z}{k}$ be linear combinations of $y{k}$ defined as in by using polynomials $f(d)$ and $p(d)$, respectively. $\bar{z}{k} \quad$ can be expressed in terms of $z{k}$ as $$ \bar{z}{k}=\sum{i=0}^{s} b_{i} z_{k-i} $$
Proof: First note that $e\left(f_{1}\right), \ldots, e\left(f_{n}\right)$ are linearly independent whenever $f_{1}, \ldots, f_{n}$ are distinct, from which it is clear that $\sum_{i=1}^{n} x_{i} \otimes e\left(f_{i}\right)=0$ implies $x_{i}=0$ for all $i$, whenever $f_{i}$ ‘s are distinct. This will establish that the processes are well defined. The second part of the lemma will follow from Lemma 4.2.10 with the choice of the dense set $\mathcal{E}$ to be $\mathcal{E}(k)$ and $\mathcal{H}=\Gamma(k)$ and by noting the fact that $\mathcal{L}, \delta, \delta^{\prime}$ and $\sigma$ have appropriate ranges. For example, $$ \left\langle e(g), a_{g}^{\dagger}(\Delta)(x \otimes e(f))\right\rangle=\langle e(g), e(f)\rangle \int_{\Delta}\left\langle g(s), \delta^{\prime}(x)\right\rangle d s, $$
证明 .
which belongs to $\mathcal{A}$, so the range of $a_{g^{\prime}}^{\dagger}(\Delta)$ is contained in $\mathcal{A} \otimes \Gamma(k)$. Similarly, one verifies that $$ \left\langle e(g), \Lambda_{a}(\Delta)(x \otimes e(f))\right\rangle=\langle e(g), e(f)\rangle \int_{\Delta}\left\langle g(s), \sigma(x){f(s)}\right\rangle d s, $$ which belongs to $\mathcal{A}$ since $\sigma(x) \in \mathcal{A} \otimes \mathcal{B}\left(k{0}\right)$.
For fixed $x \in \mathcal{A}, u \in h$ and $f \in L_{\mathrm{bc}}^{4}$, we define the integral $\int_{0}^{t} Y(s) \circ\left(a_{\delta}+\mathcal{I}{\mathcal{L}}\right)(d s)(x \otimes e(f)) u$ by setting it to be equal to $$ \int{0}^{t} Y(s)\left(\left(\mathcal{L}(x)+\left\langle\delta\left(x^{}\right), f(s)\right\rangle\right) \otimes e(f)\right) u d s $$ This integral exists and is finite since $s \mapsto Y(s)\left(\left(\mathcal{L}(x)+\left\langle\delta\left(x^{}\right), f(s)\right\rangle\right) \otimes\right.$ $e(f)) u$ is strongly integrable over $[0, t]$. We define the integral involving the other two processes, that is, $\int_{0}^{t} Y(s) \circ\left(\Lambda_{a}+a_{g}^{\dagger}\right)(d s)(x \otimes e(f)) u$ by setting it to be equal to $$ \left(\int_{0}^{t} \Lambda_{T_{x}}(d s)+a_{S_{x}}^{\dagger}(d s)\right) u e(f), $$ which is well-defined by Corollary
$$ \phi_{k}(x)=\sum_{m=1}^{N^{\prime}} L_{k}^{(m)^{*}} x L_{k}^{(m)}, \text { for all } x \in \mathcal{A} . $$ Here the Linbladian $\mathcal{L}^{\phi}$ corresponding to the partial state $\phi_{0}$ is formally given by $$ \mathcal{L}^{\phi}(x)=\sum_{k \in \mathbb{Z}^{d}} \mathcal{L}_{k}^{\phi}(x), $$
证明 .
where $$ \mathcal{L}{k}^{\phi}(x)=\phi{k}(x)-x=\frac{1}{2} \sum_{m=1}^{N^{\prime}}\left[L_{k}^{(m)^{}}, x\right] L_{k}^{(m)}+L_{k}^{(m)^{}}\left[x, L_{k}^{(m)}\right] $$
for all $\alpha \in I$, whenever $v \notin J_{0}$. Fixing this $J_{0}$, we choose $I_{0}$ to be the union of $I_{v, n}, v \in J_{0}, n=1,2, \cdots, \infty$, such that $\left\langle e\left(g^{t}+\frac{1}{n}\left(H_{I} P R_{\Delta}\right){e{\nu}, v e e\left(g_{t}\right)}\right), k_{\alpha}\right\rangle=0=\left\langle k_{\alpha}, e\left(f^{t}+\frac{1}{n}\left(H_{t}^{\prime} P S_{\Delta^{\prime}}\right){e{\nu}, u e\left(f_{t}\right)}\right)\right\rangle$ for all $\alpha \notin I_{v, n}$ when $n<\infty$, and $$ \left\langle e\left(g^{t}\right), k_{\alpha}\right\rangle=0=\left\langle k_{\alpha}, e\left(f^{t}\right)\right\rangle \text { for } \alpha \notin I_{v, \infty} $$ We now have $$ \left\langle H_{l} a_{R}^{\dagger}(\Delta)(v e(g)), H_{t}^{\prime} a_{S}^{\dagger}\left(\Delta^{\prime}\right)(u e(f))\right\rangle $$
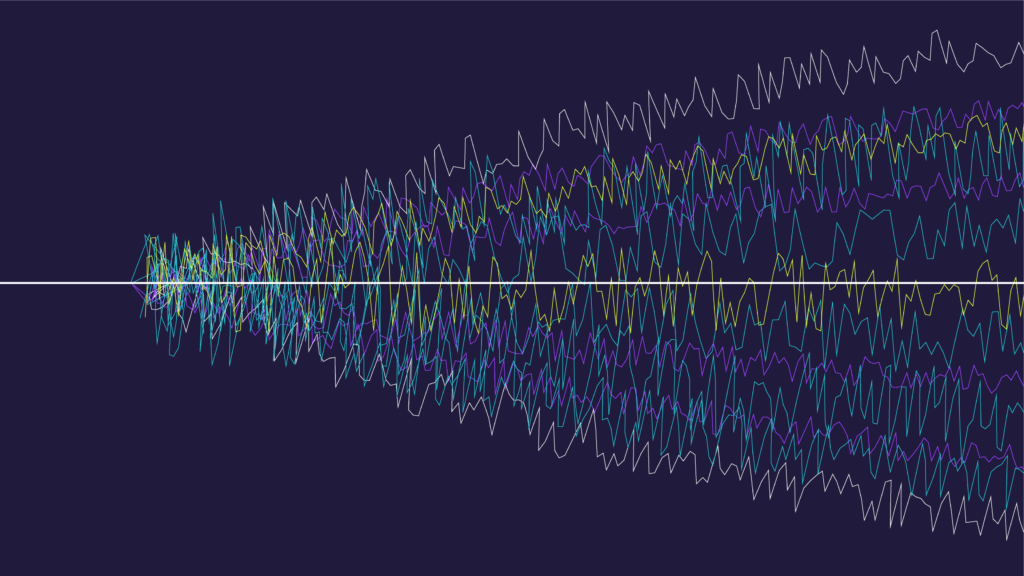
A stochastic or random process can be defined as a collection of random variables that is indexed by some mathematical set, meaning that each random variable of the stochastic process is uniquely associated with an element in the set.The set used to index the random variables is called the index set. Historically, the index set was some subset of the real line, such as the natural numbers, giving the index set the interpretation of time.
随机过程课后作业代写
If we further assume that $v_{L}$ is a function of $v$, so that all granules of a given size have the same liquid content, then $\beta$ is no longer an explicit function of $v_{L}$, and we can write: $$ \begin{aligned} \frac{\partial n(v, t)}{\partial t}=\frac{1}{2} \int_{0}^{\infty} d \varepsilon \beta(v-\varepsilon, \varepsilon) n(v-\varepsilon, t) n(\varepsilon, t) \ &-n(v, t) \int_{0}^{\infty} d \varepsilon \beta(v, \varepsilon) n(\varepsilon, t) \end{aligned} $$ This implies an equation for the mass distribution of liquid: $$ \begin{aligned} \frac{\partial M(v, t)}{\partial t}=\frac{1}{2} \int_{0}^{\infty} d \varepsilon \beta(v-\varepsilon, \varepsilon) M(v-\varepsilon, t) n(\varepsilon, t) \ &-M(v, t) \int_{0}^{\infty} d \varepsilon \beta(v, \varepsilon) n(\varepsilon, t) \end{aligned} $$ Here we recognize that for physical reasons the integrands are zero if $v_{L}$ exceeds $v$.